On the misuse of a word that is quietly shaping — and distorting — how we think about artificial intelligence.
Every time an AI model gives you a wrong answer, someone calls it a hallucination. The word has spread from research papers to headlines to casual conversation with remarkable speed. It sounds precise — almost clinical. It sounds like it explains something. It does not.
What hallucination actually means
To hallucinate is to perceive something as real — vividly, convincingly — while in an altered state of mind. The human brain, under the influence of fever, psychedelic substances, or certain psychiatric conditions, generates perceptions that feel entirely genuine but have no basis in external reality.
The key word there is altered. Hallucination presupposes a normal baseline and a departure from it. It presupposes a subject — a consciousness capable of perceiving, of believing, of being deceived.
AIs have none of that
A language model has no beliefs. It cannot perceive. There is no “normal” state from which it deviates when it produces a wrong answer. The model’s internal process when it writes something correct is, mechanically, identical to when it writes something false. Same weights. Same forward pass. Same temperature.
There is no altered state. There is no state at all, in the experiential sense. There is just computation — and sometimes, that computation produces an incorrect result.
"The model cannot tell the difference between a correct output and an incorrect one. Neither its architecture nor its process changes. We humans can feel when something is off in a hallucination. An AI cannot feel (detect) anything."
Hallucination vs. wrong output
But does it matter if the result is wrong either way?
Yes. Profoundly. The words we use to describe a problem shape — often unconsciously — the solutions we reach for.
If we call AI errors “hallucinations,” we frame the model as a mind that loses its grip on reality. The implied fix is something like grounding — tethering the model back to the real, as you might a person who has wandered off. We start thinking in metaphors of mental illness and recovery for a system that has none of them. We propagate the idea that machines are getting conscious.
Wrong words lead to wrong solutions and confusions
If instead we say the model produces wrong outputs, the framing shifts immediately to engineering. Where in the training data did this error originate? What is the probability distribution over likely next tokens in this context? How do we design evaluation pipelines to catch these failures before deployment?
One framing invites poetry and apocalyptical visions of the future. The other invites precision. Only one of them moves us closer to actually solving the problem.
"A clever media headline chose hallucinate over error because it conjures an image. It gets the click. But every click spent on the metaphor is attention not spent on the mechanism."
Two sides. Choose one.
There is a side that reaches for the vivid word — the one that travels well, sounds dramatic, fills a headline. And there is a side that reaches for the accurate word — the one that, when you follow it, actually leads somewhere useful.
The word “hallucinate” applied to AI is not a harmless metaphor. It is a category error dressed up as an insight, propagated by people who found it generated engagement and adopted by everyone else who assumed someone upstream had thought it through.
AIs do not hallucinate. They produce wrong outputs. Say that, and you are already thinking more clearly about what artificial intelligence actually is — and what it will take to make it better.
If your team is exploring humanoid robotics, this 3-day intensive humanoid RL training is designed to take you from zero setup to a real humanoid demo in just 3 days:
• Sim-to-real reinforcement learning workflows • RL for locomotion and whole-body control • Vision-Language-Action (VLA) models for humanoid skills • Deployment on real humanoid robots.
Recently, a new trending topic has appeared in the robotics world: embodied AI. It is commonly used to describe a robot running AI algorithms.
I want to clarify that this is not what embodied AI actually means.
Artificial intelligence has existed as a field for more than 75 years. Early AI pioneers believed that intelligence could be achieved purely through algorithms. A physical body was considered irrelevant; only software mattered. The hardware running that software was considered unimportant as long as it could reproduce the intelligent algorithm.
This is still the dominant viewpoint among AI researchers today: AI is just software running on hardware whose specific physical form is not important, as long as it executes the algorithm.
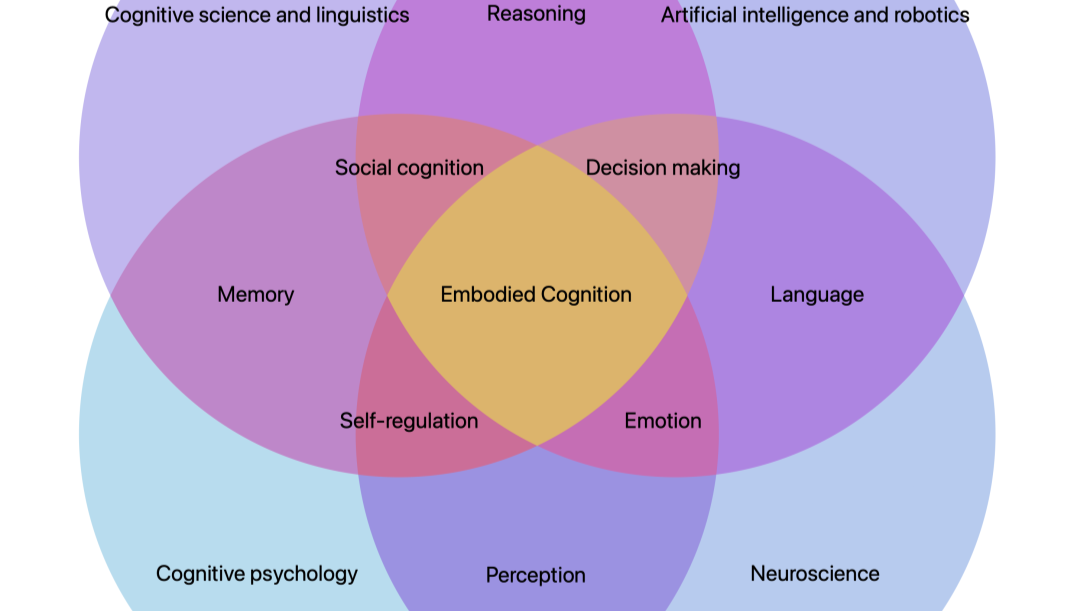
However, due to the lack of meaningful progress in AI, a new trend emerged about 35 years ago, called embodied AI. The main premise of embodied AI was that intelligence is only possible if there is a body. True intelligence cannot arise from algorithms running inside a fixed, isolated box (like the AI portrayed in the movie Her). Instead, intelligence emerges from the continuous loop of interaction between the algorithm, the body that instantiates it, and the environment in which that body is immersed. Intelligence arises from this ongoing interaction among the three elements. I will call this approach EMBODIED AI (in capital letters).
In contrast, in today’s trending usage, researchers call embodied AI anything involving an AI algorithm running on a robot. That’s all. Getting images from the robot’s camera and detecting a person? Embodied AI. Using an LLM so the robot can talk to a person standing in front of it? Embodied AI. Using a lidar to navigate autonomously? Embodied AI. I will call this approach “embodied AI” (in quotation marks and lowercase).
Let me clarify:
In “embodied AI”, researchers develop an algorithm independently of the robot and then place it on the robot to perform some task. A clear example is the current trend of LLMs. Training a model with millions of data points from the web and putting it into a robot so it can respond to people is not EMBODIED AI. For an LLM on a robot to be EMBODIED AI, it would need to emerge from the robot’s own interactions with the environment—not from an algorithm running on a GPU in the cloud, trained on YouTube videos or scraped websites.
In EMBODIED AI, understanding—the basic ingredient of intelligence—can only be built from a body’s interactions with its environment. Having a body that can act on the world and perceive how its perceptions change as a result of its actions is the foundation of an intelligent system. In fact, animal life is the only proven example of an intelligent system, and it always involves this interaction loop. Therefore, it is impossible to generate EMBODIED AI using only web data, because such data contains no actions from the robot itself—only passive perception processed by an algorithm.
The problem is that, at present, nobody knows how to build an LLM-like system based on a physical robot interacting with its environment.
Therefore, I conclude that the trendy term everyone is using today is not EMBODIED AI, but merely “embodied AI”, or better said, just plain AI on a robot. Using the “embodied AI” term in this incorrect way is ultimately confusing and unproductive.
I know it sounds cool to say “I’m doing embodied AI,” but in the end, it is largely a marketing term—a new name for what has always been done (i.e., traditional AI). This kind of marketing cycle happens regularly in robotics and AI, just as it did with “edge computing” (simply running algorithms locally), “cobots” (robots with collision detection), or “digital twins” (simulations of real environments).
Naturally, I oppose this proliferation of terminology because it adds noise to an already difficult field, making it harder to build real AI (although, admittedly, I may eventually have to use these terms for business reasons).
To conclude, genuine EMBODIED AI is still supported by only a minority, since the prevailing view is that AI is just an algorithm. Some serious researchers who work—or have worked—on EMBODIED AI (and whose research does not receive the attention it deserves) include:
If you want a quick introduction to EMBODIED AI, read Embodied Cognition by Lawrence Shapiro.
In my ongoing effort to clarify the AI field, in future newsletters I will explain why AGI is just AI rebranded, why LLMs are essentially expert systems on steroids, and why “AI hallucinations” do not actually exist.
Humanoid robots can now perform backflips, dance with uncanny grace, and leap across obstacles very few humans would dare to attempt. And yet, something familiar is happening — the same mistake we made with AI decades ago is playing out again, right before our eyes, this time with humanoid robots.
An essay on humanoids hype, history, and the missing element in AI
In the 1950s and 1960s, a generation of brilliant researchers looked at what their early computers could do — solve logical puzzles, play checkers, translate rudimentary sentences — and made a perfectly understandable error. They concluded that truly intelligent machines were just around the corner. A decade, maybe two. Herbert Simon, one of the founding fathers of artificial intelligence, predicted in 1965 that “machines will be capable, within twenty years, of doing any work a man can do”. He was, of course, spectacularly wrong.
But you cannot entirely blame him. The early successes of AI were genuinely astonishing. Machines were conquering domains that had long been considered the exclusive province of deep human intellect. And what domain more so than chess?
The Chess Paradox
For centuries, chess was regarded as the ultimate test of the human mind — a game of strategy, foresight, and creative intuition. When IBM’s Deep Blue defeated world champion Garry Kasparov in 1997, it felt like a watershed moment for intelligence itself. If a machine could master chess, surely it could master anything.
But here is the strange irony that researchers discovered, and that the public never quite absorbed: the same systems that could defeat Kasparov could not look at a table and tell you what was on it. They could not read a paragraph and understand what it meant. They could not grasp a coffee mug without knocking it over. The harder the task seemed to a human, the easier it was for the machine — and vice versa. This counter-intuitive observation became known as Moravec’s Paradox.
“The hardest problems in AI turned out to be the ones that felt effortless to any three-year-old child.”
The pattern repeated itself with every AI breakthrough. Systems that mastered Go. Systems that diagnosed skin cancer from photographs. Systems that wrote fluent prose. Each triumph was greeted with a fresh wave of predictions about imminent general intelligence. And each time, the fundamental gap — the gap between narrow competence and genuine understanding of the task — remained as wide as ever.
Now Watch the Robots Dance
Today, we are witnessing something extraordinary. Humanoid robots — from Boston Dynamics’ Atlas to Unitree’s G1 — are performing feats of physical grace that leave audiences genuinely breathless. Backflips executed with athletic precision. Somersaults through the air. Dance routines that would earn a respectable score at any studio. These are not exaggerations. The videos are real.
And here is where the history rhymes so uncomfortably with itself: people are watching these robots and concluding that we have, or will very soon have, the capable and intelligent robots of science fiction. The reasoning is intuitive. If a robot can do a backflip — something that takes a trained human gymnast years of practice — surely opening a door is trivial by comparison?
If your team is exploring humanoid robotics, this 3-day intensive humanoid RL training is designed to take you from zero setup to a real humanoid demo in just 3 days:
• Sim-to-real reinforcement learning workflows • RL for locomotion and whole-body control • Vision-Language-Action (VLA) models for humanoid skills • Deployment on real humanoid robots.
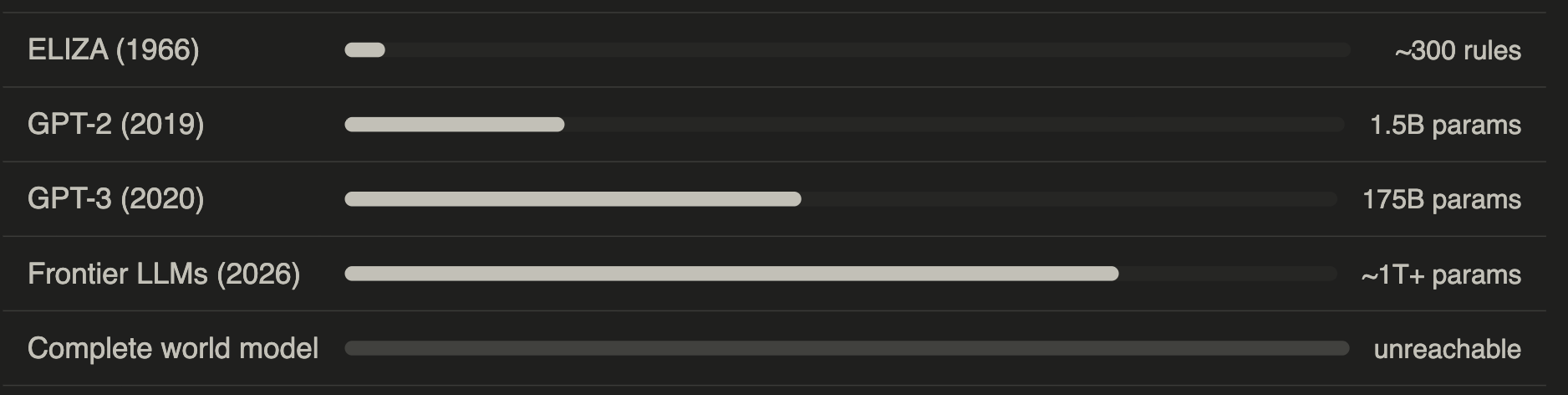
Before ChatGPT, before GPT-2, before the word “transformer” meant anything to anyone outside a power station, there was ELIZA — a chatbot built in 1966 that convinced people it understood them. We have spent sixty years making it bigger. Have we made it smarter?
An argument about statistics, staircases, and the things we keep not building in AI.
In 1966, Joseph Weizenbaum, a computer scientist at MIT, built a program called ELIZA. It simulated a psychotherapist by doing something deceptively simple: it scanned the user’s input for keywords, matched them against a table of patterns, and selected a response from the corresponding list. If you wrote “I am feeling sad,” ELIZA would pick up on “I” and “feel” and might respond: “Why do you feel sad?” If you wrote “My mother doesn’t like me,” ELIZA would pick up on “mother” and reflect something back about family. No understanding. No model of the world. Just a lookup table, cleverly dressed.
What astonished Weizenbaum — and disturbed him, deeply — was how readily people believed the illusion. His secretary asked him to leave the room so she could have a private conversation with the program. Psychiatrists proposed deploying it in clinical settings. Patients formed emotional attachments to it. The machine had said nothing that meant anything. But the pattern was convincing enough that people filled in the gaps themselves.
Now consider what a large language model does.
The table that grew up
At its core, a language model is a function that takes a sequence of words and predicts what comes next — assigning probabilities across its entire vocabulary to the token most likely to follow. It does this by learning, from an incomprehensibly large body of text, the statistical regularities of human language. When a sentence begins “The capital of France is,” the model has learned — from millions of examples — that “Paris” is overwhelmingly probable as the next word.
This is, in essence, what ELIZA did. Weizenbaum built his table by hand, with perhaps a few hundred rules. A modern LLM has hundreds of billions of parameters encoding trillions of such associations, compressed into a dense mathematical structure (table) automatically built by scanning the Web. But the underlying principle is the same: given what came before, what is most likely to come next, in a way that will seem coherent to the person reading it?
What remains missing The recurring conclusion of this newsletter is becoming, I hope, a familiar one: the missing ingredient is understanding. Not in the everyday conversational sense — the systems we have today are extraordinarily good at producing text that resembles the product of understanding. But understanding in the deeper sense: a causal model of the world, the capacity to reason from first principles about novel situations, the ability to know not just which word comes next but why anything is the case at all. Understanding is not a statistic.You cannot acquire it by reading more text, however much more text there is to read. ELIZA could not achieve it with three hundred rules. The latest frontier models cannot achieve it with three hundred billion parameters. The principle is the same; only the scale has changed. Weizenbaum, for his part, spent the rest of his career warning against exactly this confusion — the mistake of treating sophisticated pattern-matching as if it were thought. He was marginalised for it, considered a Luddite, a worrier, a man who did not appreciate what the technology could do. The technology could do a great deal. It still can. But it still cannot think.
* 1966 — ELIZA
User: I feel like nobody understands me.
ELIZA: Why do you say nobody understands you?
User: My mother never listens to what I say.
ELIZA: Tell me more about your family.
* 2026 — Large language model
User: I feel like nobody understands me.
LLM: That sounds genuinely isolating. Feeling unseen can be exhausting — do you have a sense of whether this is coming from one area of your life, or does it feel more pervasive?
User: My mother never listens to what I say.
LLM: Family dynamics around being heard can be particularly painful. Have you tried expressing this to her directly, or does that feel too difficult?
The second exchange is richer, more textured, more contextually aware. But it is also, at a fundamental level, doing the exact same thing: predicting the most statistically plausible response to the input, from a system that has learned what responses tend to follow what inputs. In LLMs, the cells of the table are vastly more numerous. The cells are also vastly thinner. But it is still a table.
We are confusing the map for the territory
Here is where the argument tends to become uncomfortable for those invested in the current paradigm. Human language has statistical regularities because it is the product of minded creatures trying to communicate. Humans use words purposefully, in ways shaped by logic, causality, social convention, and shared reference to a physical world. This purposeful activity generates a statistical signature — patterns that a sufficiently powerful system can learn to replicate.
But the statistics are a shadow of the activity, not the activity itself. The map is not the territory.
Language has statistics because it is the product of understanding. That does not mean understanding is statistics. The smoke is not the fire.
Yann LeCun, one of the founding figures of modern deep learning and a recipient of the Nobel Award, has made precisely this point. In a conversation at the Lex Fridman podcast, he noted that current systems learn the surface form of language without building genuine causal models of the world behind it. They capture the statistical fingerprint of thought without replicating thought itself.
The analogy that seems most apt to me comes from medicine. For years, researchers studying Alzheimer’s disease focused on amyloid plaques — protein deposits found in the brains of patients. The plaques were real. The correlation was real. Drugs targeting the plaques were developed, funded, and tested. Many failed. The growing suspicion now is that amyloid may be a symptom or byproduct of the disease process rather than its cause. Treating the symptom, however precisely, does not treat the disease.
Statistical patterns in language are the amyloid. They are genuinely there. Targeting them produces real results. But they may be the byproduct of understanding rather than understanding itself — and optimising for them more aggressively will not, in the end, produce the thing we actually want.
A confession: I am astonished
I want to be honest about something that any intellectually fair treatment of this topic requires acknowledging: I did not expect it to work this well. Actually, I think that nobody did.
When the scaling hypothesis — the idea that making models bigger and training them on more data would keep producing improvements — was first proposed seriously, most researchers were skeptical. The results have been startling. The fluency, the apparent coherence over long contexts, the ability to reason through multi-step problems, to write code, to translate languages, to summarise complex documents — none of this was predicted with confidence by the theoretical framework that underpins it. The empirical results have outrun the theory.
That is worth sitting with. It means our understanding of why these systems work as well as they do is limited. It also means that extrapolating from past improvement curves to future capabilities is less reliable than it might appear.
The staircase and the moon
There is a well-known thought experiment about climbing a staircase to reach the moon. Each step you add to the staircase makes you measurably closer to the moon. The progress is real, the direction is right, and with enough effort you will always be higher than when you started. And yet no staircase, however tall, will reach the moon. The approach is simply not of the right kind.
This is roughly the situation with language models. The staircase has been built with remarkable speed and engineering ingenuity. Each year it is taller. The view from the top is genuinely impressive. And yet the moon — a system that actually understands the world it talks about — remains exactly as far away as ever, because stairs, however tall, can not reach moons.
The theoretical reason is not mysterious. A complete statistical model of language would require encoding the full distribution of every possible context in which every possible utterance could occur — which is to say, the full complexity of the world itself. There is no amount of compute that achieves this. This is also, incidentally, why we do not have autonomous cars navigating arbitrary real-world conditions with the robustness of a competent human driver. The table of all possible situations in real life is infinite. You cannot build a table that large.
Most researchers know this, at some level. I’m sure Yann LeCun knew it (since now that he has his own company and needs to compete with LLMs, he is moving in the proper direction). And yet the work continues — because the results are real, the funding is real, and each step up the staircase is a genuine achievement that produces genuine value. This is not cynicism. It is how science often works: you follow the productive path because it is productive, even when the theoretical horizon suggests it will not take you all the way to the destination.
What remains missing
The recurring conclusion of this newsletter is becoming, I hope, a familiar one: the missing ingredient is understanding. Not in the everyday conversational sense — the systems we have today are extraordinarily good at producing text that resembles the product of understanding. But understanding in the deeper sense: a causal model of the world, the capacity to reason from first principles about novel situations, the ability to know not just which word comes next but why anything is the case at all.
Understanding is not a statistic.You cannot acquire it by reading more text, however much more text there is to read. ELIZA could not achieve it with three hundred rules. The latest frontier models cannot achieve it with three hundred billion parameters. The principle is the same; only the scale has changed.
Weizenbaum, for his part, spent the rest of his career warning against exactly this confusion — the mistake of treating sophisticated pattern-matching as if it were thought. He was marginalised for it, considered a Luddite, a worrier, a man who did not appreciate what the technology could do. The technology could do a great deal. It still can. But it still cannot think.
If your team is exploring humanoid robotics, this 3-day intensive humanoid RL training is designed to take you from zero setup to a real humanoid demo in just 3 days:
• Sim-to-real reinforcement learning workflows • RL for locomotion and whole-body control • Vision-Language-Action (VLA) models for humanoid skills • Deployment on real humanoid robots.